



The capabilities of an AI system can be enhanced in two ways: by increasing compute allocated to training (producing a bigger model), and by increasing compute allocated to inference (employing post-training techniques, like chain-of-thought).
For example, a great deal of current frontier model weights are used to memorize facts. These models can be prompted to recall facts efficiently - they reach into their model weights and immediately produce the answer. The inner workings of this process are a black box for which the field of interpretability is aimed at decoding.
By contrast, current frontier models seem to have a hard time doing math. Instead of immediately producing mathematically correct answers, they produce incorrect answers consistently. However, by using more inference, for example, asking an LLM to work step-by-step, the program can get more accurate answers.
One comparison between these two modes of answering is that has been made is that instant answers are like System 1 and answers from further inference are like System 2, popularized by Daniel Kahneman, which correspond to the concepts of intuition as opposed to reasoning. Human reasoners often develop intuition for certain kinds of cognitive tasks - like an LLM, they can reach into their unconscious and immediately produce an accurate answer or correct reaction to a situation. By contrast, human intuition fails at many tasks that a step-by-step process allows us to work through more effectively. We engage in explicit System 2 reasoning in a step-by-step procedure using our prefrontal cortex (see, for example, Owain Evans discussion here and here of in-context vs out-of-context learning and “doing computation in the forward-pass” e.g. intuition, under the hood, in the black box).
We can imagine these two sources of capabilities as existing on an x-y graph, as Epoch AI illustrates:

So some amount of capabilities improvement from training can be equivalent to some amount of capabilities improvement from post-training enhancement.
Furthermore, there seems to me to be a progressive relationship between intuitive and reasoned capabilities in an optimally productized model. An AI system reasons explicitly only upon/by using its intuition - that is to say, its explicit reasoning emerges and builds atop from its implicit reasoning (intuition, System 1, the black box). If an AI model knows the answer to some question is X when queried and given no post-training enhancements like the ability to think for a while or other tools, then it should be able to produce the answer X when queried just as fast when it is enhanced post-training.
Taking the analogy further, another notable feature of human intuition which appears to hold for AI intuition is that it is malleable. People can develop an intuition for some of the most unintuitive things by regular training and interaction with those things. For example, instead of using computers, Achim Leistner smoothed out the world’s roundest sphere by hand. AI systems, it seems, can gain intuitive capabilities by simply doing training runs or fine-tuning on the relevant domain - much like human intuition is built up by interacting with the material in great quantities, enough to build that intuition out.
Because the training/intuition and inference/reasoning analogy is progressive and uneven, we can reconceive of the landscape of tasks that an AI can perform as vertically stratified. The most famous visual aid in conceiving the growth of AI capabilities is Max Tegmark’s illustration of Hans Moravec’s 1998 analogy of a physical landscape being flooded by AI capabilities as they improve:

In this metaphor, the sea level represents the frontier of AI capabilities. As AI improves, the sea level rises, allowing AI to carry out tasks that were previously outside of its reach.
But if there is a meaningful difference between training-based and inference-based capability gains, and they have a progressive relationship (one builds outward off the other), we can instead look at Moravec’s sea from the side, as layers in an ocean:

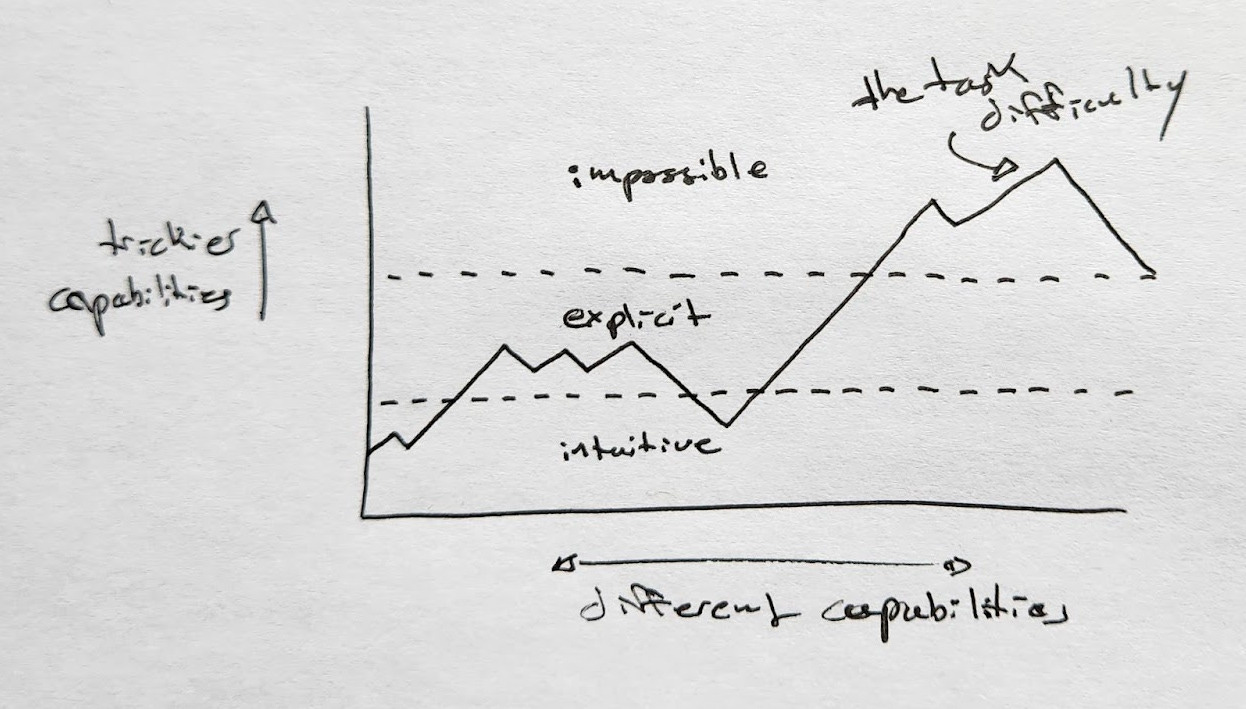
In this model, Moravec’s sea is stratified into two layers: an abyssal layer of intuition-like capabilities baked into the black box of a model, and a bathyal layer that a given level of intuition can reach out above the abyssal layer. Tasks in the abyssal layer are achievable without needing additional inference - the AI system simply outputs the answers immediately. Tasks in the bathyal layer are achievable, but only by expending inference compute on a model of a given abyssal level.
In this model, Moravec’s sea is stratified into two layers: an abyssal layer of intuition-like capabilities baked into the black box of a model, and a bathyal layer that a given level of intuition can reach out above the abyssal layer. Tasks in the abyssal layer are achievable without needing additional inference - the AI system simply outputs the answers immediately. Tasks in the bathyal layer are achievable, but only by expending inference compute on a model of a given abyssal level.
The existing suite of inference-intensive methods for improving model performance are almost certainly incomplete. One obvious additional approach, especially if the analog of human reasoning holds, is to employ multiple LLM agents together, or give one LLM agent tons of time to think to itself, to generate a third stratum, perhaps a epipelagic layer. This follows from the human analogy because human intelligence is not only born of intuition and reasoning, but also collectively from multiple minds working together, or a single person being given more time to think about a problem from multiple angles. An LLM with a high water mark for both its intuition and explicit reasoning processes may achieve even higher sea level by multiplying the number of them working together.
What distinguishes a collective or durational intelligence approach to inference-intensive algorithmic improvements is that it would seem much more likely to be unbounded. A given model is only going to benefit so much from a given additional reasoning technique. By contrast, by simply multiplying the number of LLMs, or giving them tons of runway to think and probe and work through a task, it would seem that any system that has sufficient innate generality as a consequence of it Systems 1 should in-principle be able to achieve tasks of any height on Moravec’s landscape. The question would come down to compute cost. Note this would only apply to systems that have sufficient generality already - an unlimited number of calculators or GPT-3s would probably not cause emergent generality because they don’t have enough generality innate to their systems (one being strictly narrow, and the other being perhaps a bit too noisy).
If this argument is true, it follows that an artificial general intelligence or human-level advanced AI does not require a massive additional training run. Instead, it is likely to be accomplishable by algorithmically enhancing and orchestrating numerous sub-general AI systems.
Cool metaphor!
I wonder if the better metaphor for the difference between the intuitive/inferential phases is the difference between sea and air, not the difference between different phases of the water column.
Consider: Moravec's Sea is a compelling metaphor because it helps explain the phenomenon of "AI getting really good at everything all at once"; all those things its getting good at are at the same height above sea level, so as the water rises, they are all flooded.
Is Inference (or the post-Inference steps you describe) like this? It seems more like you need a different series of explicit steps to achieve the desired result for each application; it's a bit like the AI has taken its first steps onto land, and is now trying to scale new heights. It wouldn't reach all peaks simultaneously; instead, it would plan its ascent, peak by peak, determining the right path to the top.